
Information-Driven Software Engineering

Projektgruppe
(Veranstaltungsnummer: L.079.07007)
In heutigen Software Engineering (SE) Prozessen werden als Ergebnis der einzelnen Prozessphasen unterschiedliche Artefakte erstellt. Die Artefaktpalette reicht von textuellen Beschreibungen von Anwendungsszenarien, über UML-Diagramme bis zum eigentlichen Programmcode. Erkennung, Verwaltung und Nachvollziehbarkeit vorhandener Beziehungen zwischen den Artefakten stellen ein zentrales Problem innerhalb des SE-Prozesses dar, da diese Tätigkeiten aufwendige manuelle Schritte erfordern.
In jüngster Zeit wird in Forschung und führender Industrie untersucht, wie sich semantische und intelligente Technologien in das Management dieser Artefakte integrieren lässt. Solche Technologien beruhen auf der automatischen Gewinnung von Informationen und nutzen diese, um die Bedeutung und Zusammenhänge der Artefakte automatisch sichtbar und verarbeitbar zu machen.
Ziel der Projektgruppe ist die Entwicklung von State-of-the-Art-Verfahren zur Erkennung semantischer Informationen in SE-Artefakten mittels Information-Extraction-Techniken. Anhand dieser Informationen soll untersucht werden, welche Artefakte sich automatisiert verarbeiten und ggf. sogar erzeugen lassen und wie sich die Nachvollziehbarkeit des Prozesses verbessern lässt.
Betreuer der PG:
Die Projektgruppe im Bild:


Motivation
Natürlichsprachlicher Text ist nach wie vor die meist verbreitetste Form zur Spezifikation von Software-Systemen. Derartige Spezifikationen können leicht mehrere hundert oder tausend Seiten umfassen. Ein Beispiel: Die Spezifikation der deutschen elektronischen Gesundheitskarte und der zum Betrieb notwendigen Infrastruktur, genannt die Telematik-Infrastruktur, umfasst etwa 30 Dokumente mit einem Gesamtvolumen von mehr als 10.000 Seiten. Die Spezifikation entsteht unter Federführung der eigens hierfür gegründeten Gematik, die alle Interessensverbände wie Krankenkassen, Ärzte, Krankenhäuser und Apotheken zusammenbringt. Dementsprechend ist die Erstellung der Spezifikation ein langwieriger Prozess, mit vielen Einflussgrößen und einer großen Anzahl an Autoren.
Eine derart umfassende Spezifikation birgt sowohl bei ihrer Erstellung als auch bei ihrer Verwendung einige Probleme in sich.
- Wie kann sichergestellt werden, dass die Spezifikation konsistent ist und keine Widersprüche enthält?
- Wie beherrscht man die Komplexität der Anforderungen?
- Ist eine solche Spezifikation eindeutig, so dass keine Inkompatibilitäten bei ihrer Implementierung auftreten können?
- Wie können Modelle abgeleitet werden, die den weiteren Entwicklungsprozess unterstützen?
Ziele
Die PG ID|SE setzt sich zum Ziel, derartige Probleme mit neuesten Forschungsansätzen anzugehen. Hierzu werden Techniken des Information-Extraction mit Modellierungsansätzen aus dem Software Engineering kombiniert.
Information-Extraction-Techniken verwenden dazu oft Methoden der KI, um aus natürlichsprachlichem Text Informationen zu extrahieren. Diese Informationen können wiederum verwendet werden, um z.B. Rückschlüsse auf die Konsistenz einer Spezifikation zu ziehen. Außerdem sollen diese Informationen mit Modellierungstechniken des Software-Engineerings, wie UML Diagrammen, verknüpft bzw. Modelle automatisch generiert werden. Ziel ist, den Softwareentwicklungsprozess durch die automatische Verknüpfung von Informationen zu verbessern.
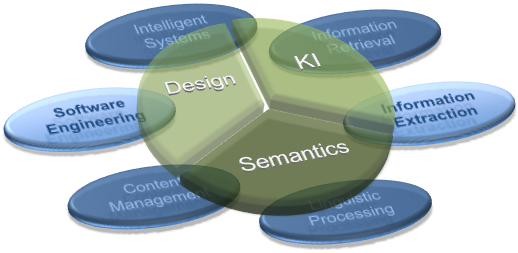
Aufgaben in der PG
Grundlage für die Implementierung der in der PG entwickelten Verfahren, Algorithmen und Technologien soll ein Content Management System (CMS) für das Software Engineering sein. In diesem CMS werden Artefakte wie Anforderungsbeschreibungen, Entwurfs- und Design-Dokumente sowie UML Diagramme abgelegt. Die entwickelten Verfahren werden dann als Komponentenbausteine dieses CMS mit semantischen und intelligenten Features erweitert. So soll es möglich werden, die Informationsflut zu bewältigen, indem Artefakte im CMS analysiert, Informationen automatisch strukturiert und neue Artefakte erzeugt werden.
Eine grobe Liste der Aufgaben umfasst folgende Punkte, wobei Details selbstverständlich von der PG selbst festgelegt werden.
- Auswahl eines (Open Source) CMS, auf dem man aufbauen kann.
- Erweiterung des CMS als CMS für das Software Engineering, um die Artefakte des Software Engineerings ablegen und verwalten zu können.
- Entwurf und Implementierung von intelligenten Verfahren, die helfen, die anfallenden Informationen zu strukturieren und zu verarbeiten, um z.B. Redundanzen oder auch Inkonsistenzen aufzudecken.
- Entwurf und Implementierung von Komponenten zur Verarbeitung und ggf. Erzeugung von UML Modellen.
Die Implementierung soll in der Programmiersprache Java und ggf. JavaScript erfolgen, da die meisten CMS web-basierte Lösungen sind. Um das Rad für viele Probleme nicht neu zu erfinden, soll die PG auf bestehende Technologien, idealerweise Open Source Produkte, zurückgreifen. Die geschickte Wiederverwendung und Integration von bestehenden Softwarekomponenten ist ebenfalls Ziel der PG.
Hintergrund
Die PG befasst sich mit einem real existierenden Problem, das etwa für das Beispiel der elektronischen Gesundheitskarte den Projekterfolg maßgeblich gefährdet. Die Herangehensweise unter Einbeziehung aktueller Forschungsergebnisse erfolgt im Einklang mit laufenden internationalen Forschungsprojekten, die von der FG Datenbank- und Informationssysteme durchgeführt werden. Die Ergebnisse der PG werden in die aktuelle Forschung dieser Projekte eingebunden, so dass die Nachhaltigkeit der Arbeit in der PG gesichert ist.
Aktuelle Forschungsprojekte

In Zusammenarbeit mit