
Entwicklung einer XML-basierten visuellen Shading Language
Diplomarbeit von Ralf Borau
Motivation
Über viele Jahre begnügten sich 3D-Grafik-Systeme mit festen parametrisierten Funktionen, um Schattierungs- und Reflexionsmodelle zu berechnen. Gouraud-Shading oder das Phong-Reflexionssmodell sind effizient und genügten bis zu einem gewissen Grad den qualitativen Ansprüchen.
Einen Weg zu mehr Realismus und größerer Flexibilität stellen prozedurale Shader dar. Dieses sind abgeschlossene Programme, die beispielsweise statt eines festen Beleuchtungsmodells ausgeführt werden, um einen Farbwert zu errechnen. Mit ihnen hat der Anwender die Möglichkeit, die Darstellung von 3D-Modellen (-Daten) selbst zu bestimmen. Die Programmiersprache zur Programmierung dieser Shader nennt man Shading Language.
Um von den Vorteilen der programmierbaren Shader profitieren zu können, wurden programmierbare Prozessoren (Vertex- und Fragment-Prozessoren) in moderne Grafikkarten integriert. Mit ihnen lassen sich neue Grafikeffekte für Visualisierungen oder 3D-Computerspiele in Echtzeit nutzen. Vertex- und Fragment-Programme sind assembler-ähnliche Programme, die von den entsprechenden Prozessoren ausgeführt werden. Solche Programme in Assembler zu programmieren ist schwierig und mühselig. Analog zur herkömmlichen Programmierung ergibt sich daraus die Forderung nach einer Programmiersprache, die mehr Komfort und ein höheres Abstraktionslevel bietet. Die bisherigen Entwicklungen in diesem Bereich gehen in eine ähnliche Richtung. Die Shader können mit einer prozeduralen Programmiersprache geschrieben werden, und ein Compiler erzeugt daraus ein Vertex- oder Fragment-Programm. Diese Sprachen werden als High-Level Shading Languages (HLSL) bezeichnet. Beispiele hierfür sind die High-Level Shader Language, C for graphics (Cg) und die OpenGL Shading Language (GLslang).
Obwohl sich die HLSLs als High-Level bezeichnen, sind diese Sprachen bewusst allgemein gehalten und lassen ein anwendungsbezogenes Abstraktionslevel vermissen. Ziel dabei ist eine möglichst breite Nutzung der verfügbaren Hardware. Menschen ohne Programmierkenntnisse bleiben die Möglichkeiten dieser neuen Technik verschlossen. Der Bereich der Visuellen Programmierung könnte an dieser Stelle Abhilfe schaffen.
Die Verknüpfung von Visueller Programmierung und Grafikprogrammierung ist nicht neu. Ein bereits aus dem Jahr 1984 stammendes Konzept sind die Shade Trees. Bei Shade Trees werden Shader als große Baumstruktur dargestellt und entwickelt. Knoten innerhalb des Baumes können sowohl einfache als auch komplexe Operationen, wie Vektor- und Matrix-Operationen, sein. Operanden sind die Ergebnisse der jeweiligen Teiläste. Eine Implementierung der Shade Trees wurde von Abram und Whitted vorgestellt. Es ist ein Shader-Entwicklungssystem, das aus zwei Teilen besteht. Der erste High-Level-Teil besteht aus Blöcken fester Funktionalität, die man in einem Netzwerk miteinander verknüpfen kann, um Shader zu programmieren. Dieser Teil kann auch von Anwendern ohne das Erlernen einer Programmiersprache genutzt werden. Der zweite Teil ist eine herkömmliche Programmiersprache, mit der sich neue Blöcke programmieren und dem System hinzufügen lassen.
Die Entwicklung von Vertex- und Fragment-Programmen kann durch die Visuelle Programmierung vereinfacht werden. Dadurch können Shader schneller und robuster entwickelt werden. Aus diesem Grund wurde eine visuellen Shading Language sowie ein auch in Java geschriebenes Entwicklungssystem geschaffen. Das XML-Datenformat wurde hinsichtlich einer Integration in X3D auch berücksichtigt.
Das Datenflussmodell
Grundmodell der visuellen Sprache
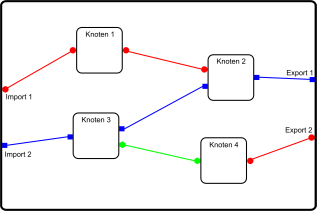
Das Grundmodell der visuellen Shading Language basiert auf dem Datenflussmodell, d.h. Vertex- oder Fragment-Programme werden als Datenflussdiagramme dargestellt. Ein solches Diagramm besteht aus Knoten mit Ein- und Ausgängen, die über Kanten miteinander verbunden werden können. Abbildung 1 zeigt beispielhaft ein solches Diagramm. Die Ein- und Ausgänge der Knoten werden als farbliche Symbole auf der linken bzw. rechten Seite des Knotens dargestellt. Diese Symbole sind Start- und Endpunkte (Anschlüsse) für die Kanten, die einen Eingang mit einem Ausgang verbinden. Dabei kann ein Ausgang mit mehrere Eingängen verbunden werden. Den Ein- und Ausgängen ist jeweils ein eindeutiger Datentyp zugeordnet, und eine Verbindung kann nur zwischen Anschlüssen gleichen Typs hergestellt werden. Je nach Datentyp unterscheiden sich Farbe und Form des Symbols. Eine Kante wird mit der entsprechenden Farbe der verbundenen Anschlüsse eingefärbt. Die Daten fließen auf den Kanten in einem solchen Diagramm immer von links nach rechts. An der linken und rechten Seite des Diagramms sieht man Anschlüsse, die keinem Knoten zugehörig sind. Sie entsprechen im klassischen Datenflussmodell den Datenquellen und -senken und stellen Schnittstellen nach außen dar. Nachfolgend werden diese auch Import- und Export-Anschlüsse genannt.
Ausführung und Ausführungsmodell
Dieses Modell ist speziell für die visuelle Beschreibung von Vertex- und Fragment-Programmen gedacht. In der Praxis muss eine Konvertierung in ein äquivalentes Programm einer normalen Shading Language erfolgen, damit der Shader auf der Grafikkarte ablaufen kann. Eine Implementierung dieses Modells als visuelle Programmiersprache ist deshalb immer an eine High-Level Shading Language (z.B. Cg oder glsang) gekoppelt, für die ein Programm visuell entwickelt wird. Die Ausführung als Datenflussprogramm ist deshalb nur modellhaft zu verstehen. Dennoch wird das Ausführungsmodell kurz erläutert.
Beim Start eines Datenflussprogrammes liegen an allen Eingabeschnittstellen Daten an. Anliegende Daten fließen automatisch über die Kanten an die damit verbundenen Knoten. Ein Knoten bildet eine funktionale Einheit. Sobald an allen Eingängen Daten bereitstehen, wird diese Einheit ausgeführt. Die Ausführung eines Knotens erzeugt an allen Ausgängen Ausgabedaten, die über alle verbundenen Kanten wiederum an die Eingänge anderer Knoten fließen. Ein Datenflussprogramm ist beendet, falls kein Knoten mehr ausgeführt werden kann. Im Idealfall sind alle Knoten einmal ausgeführt worden, und an allen Ausgabeschnittstellen liegen Daten vor.
Vorteile
Der größte Vorteil dieses Modells gegenüber der herkömmlichen Programmierung ist seine Robustheit. Wenn das Entwicklungssystem bei der Erstellung eines solchen Diagramms nur gültige Knoten und Kanten zulässt, sind syntaktische Fehler praktisch ausgeschlossen. Auch Fehler, die durch die Verknüpfung inkompatibler Datentypen entstehen, sind damit unmöglich. Seiteneffekte durch die Verwendung von globalen Variablen kann es nach diesem Modell auch nicht geben.
Hinzu kommt, dass die Programmierung mit dieser Sprache sehr leicht erlernbar ist. Im Vergleich zu prozeduralen Sprachen gibt es nur sehr wenig Syntaxregeln. Die Eigenschaft, fast nur lauffähige Programme erzeugen zu können, ist für den Einstieg auch sehr hilfreich.
Ein weiterer Vorteil liegt in der visuellen Strukturierung eines Programms. Voneinander unabhängige Programmteile sind klar voneinander getrennt und werden als parallele Abläufe sichtbar. Abhängigkeiten sind dagegen dadurch ersichtlich, dass sie hintereinander geschaltet sind.
Visuelle Shading Language für Cg und OpenGL
Auf Basis des Grundmodells wurde eine visuelle Programmiersprache geschaffen, die auf der High-Level Shading Language Cg aufsetzt und mit der OpenGL Vertex- und Fragment-Programme entwickelt werden können.
Abbildung 2 zeigt die Verarbeitungsschritte eines visuellen Shaders hin zu einem ARB-Programm. Aus der visuellen Darstellung als Datenflussdiagramm wird als erstes ein XML-Dokument generiert (Export). Dieses kann eine XML-Datei oder ein DOM-Dokument im Speicher sein. Das Dokument wird dann durch eine XSL-Transformation in ein Cg-Programm überführt. Diese Programm muss abschließend nur noch durch den Cg-Compiler in einen OpenGL-Shader übersetzt werden.
Datentypen
Die Darstellung eines Anschlusses ist vom zugeordneten Datentyp abhängig. Wichtig dabei ist, dass der Benutzer schnell und eindeutig die Verknüpfungsmöglichkeiten zwischen Ein- und Ausgängen erkennen kann. Dazu müssen sich die Darstellungen verschiedener Datentypen klar voneinander unterscheiden. Eine leichte Erkennung des zugeordneten Datentyps ist ebenfalls ein wichtiges Ziel. Dieses sollte für den Benutzer auch ohne lange Lernphasen möglich sein.
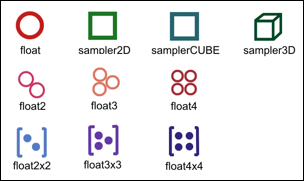
Abbildung 3 zeigt die Symbole der verfügbaren Datentypen. Die einfache Datentypen sind in der ersten Zeile zu sehen. Sie werden durch ein einfaches geometrisches Objekt dargestellt. Beim Gleitkomma-Datentyp \textit{float} ist es ein Kreis. Die beiden Textur-Referenzen \textit{sampler2D} und \textit{samplerCUBE} werden beide als Quadrat dargestellt, da beide auf eine 2-dimensionale Textur verweisen. Analog wird die Referenz auf eine 3D-Textur als Kubus dargestellt. Die Vektor-Typen bilden die mittlere Zeile. Die Symbole enthalten sowohl eine Information über den Grunddatentyp als auch über die Anzahl der Komponenten, z.\,B. vier Kreise für einen Vektor mit vier Gleitkomma-Komponenten. Die unterste Zeile zeigt die Matrix-Typen. Die umgebenen eckigen Klammern sollen an die übliche Matrix-Darstellung erinnern. Da nur noch quadratische Matrizes unterstützt werden, kann mit zwei, drei oder vier Punkten die Matrix-Größe angegeben werden.
Man sieht, dass die Datentypen alleine durch ihre Form identifizierbar sind. Neben der Form unterscheiden sich alle Symbole zusätzlich noch durch ihre Farbe. Dieses soll hauptsächlich einer schnellen Unterscheidbarkeit dienen, kann aber durch Erfahrung auch der Identifizierung helfen.
Knotentypen
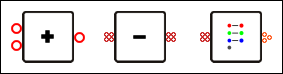
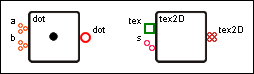
Für eine Implementierung mit Cg und OpenGL hat sich die Unterscheidung verschiedener Knotentypen als nützlich erwiesen. Es gibt Operator-, Funktions-, Diagramm- und konstante Knoten. Ihre jeweilige visuelle Repräsentation wird hier beispielhaft gezeigt.
Für den praktischen Einsatz mit Cg unter OpenGL sind folgende zwei zusätzlichen Knotentypen notwendig. In Cg werden die OpenGL-Programmparameter durch eine spezielle Datenstruktur zur Verfügung gestellt. Über die globale Variable glstate kann auf diese Daten zugegriffen werden. Die Datenstruktur unterteilt die Parameter in die drei Bereiche Matrix, Material und Licht. Um diese Parameter auch in der visuellen Sprachen nutzen zu können, wurde ein neuer Knotentyp geschaffen. Dieser Knotentyp ist den konstanten Knoten sehr ähnlich. Auch der OpenGL-State-Knoten liefert nur einen Datenwert.
Weil es bisher nicht möglich ist, verschiedene Komponenten zu einem Vektor zusammenzufügen, ist ein weiterer Knotentyp notwendig. Der Konstruktorknoten hat mehrere Eingänge und einen Ausgang, der einen Vektor-Datentyp liefert.
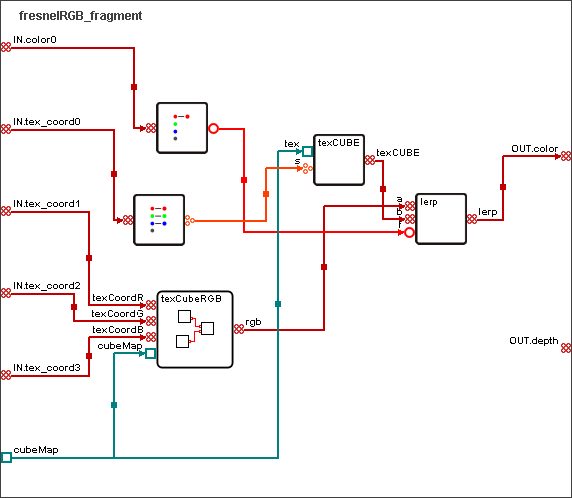
Beispiel Shader
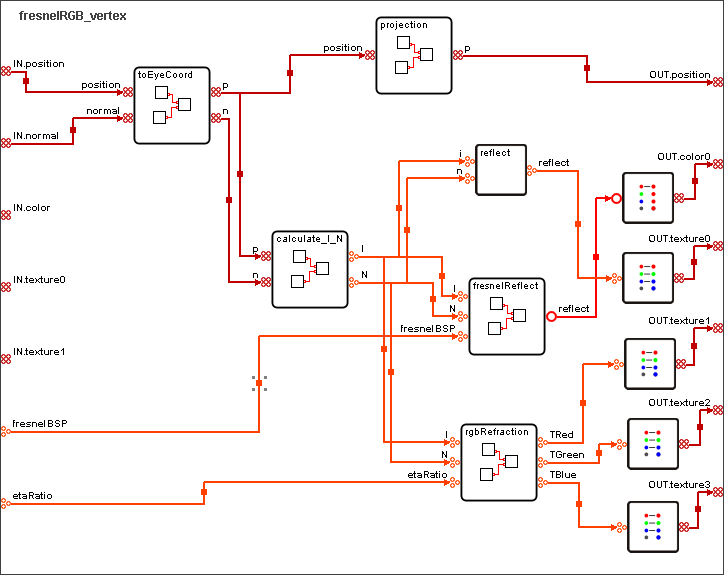
Das nachfolgend abgebildete FresnelRGB-Shader beruht auf dem Chromatic Dispersion Shader aus The Cg-Tutorial von Fernando und Kilgard. Dieses Beispiel zeigt, dass auch sehr komplexe Shader übersichtlich und strukturiert mit der visuellen Shading Language programmiert werden können. Zwei physikalische Effekte werden in diesem Beispiel approximiert, der Fresnel Effekt und Dispersion des Lichts.
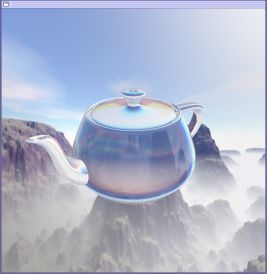
Preview
Abbildung 4 zeigt nun das Preview-Fenster des Editors mit aktiviertem Fresnel\-RGB-Shader. Die Cube Map zeigt ein zerklüftetes Bergpanorama. Die verwendeten Bilddateien stammen aus dem
Cg Toolkit
von NVIDIA. Die rückseitige Fläche der Cube Map wird als Hintergrund angezeigt. Als Testobjekt wurde für diesen Shader die Teekanne ausgewählt. Man kann deutlich die Spiegelung der Umgebung auf der Kanne erkennen. Der Berechungsindex ist sehr hoch gewählt, so dass das gebrochene Licht ein sehr verzerrtes Bild ergibt. Die Dispersion macht sich durch bunte Schlieren bemerkbar. Diese entstehen durch harte Hell-Dunkel-Übergänge. In diesem Beispiel ist es der Kontrast zwischen den dunklen Bergen und dem hellen Himmel.Download
Visual Editor
: Auf Java basierendes visuelles Entwicklungssystem.